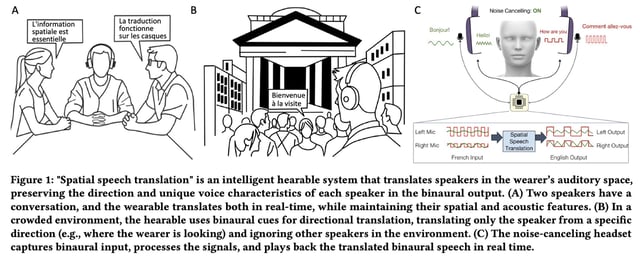


Overview
- Spatial Speech Translation uses off-the-shelf noise-cancelling headphones and binaural microphones to separate, track, and translate multiple speakers with a 2–4 second delay.
- The system preserves each speaker’s unique voice traits and spatial directionality, even as they move through a 360-degree adaptive tracking algorithm.
- All processing occurs locally on Apple M2-powered devices, such as laptops and Vision Pro, avoiding cloud computing to safeguard user privacy.
- Tested in 10 diverse environments, the system outperformed non-tracking models in user preference, with participants favoring a 3–4 second delay for accuracy.
- The proof-of-concept code has been released as open-source, enabling further development and potential expansion to more languages beyond Spanish, German, and French.