Overview
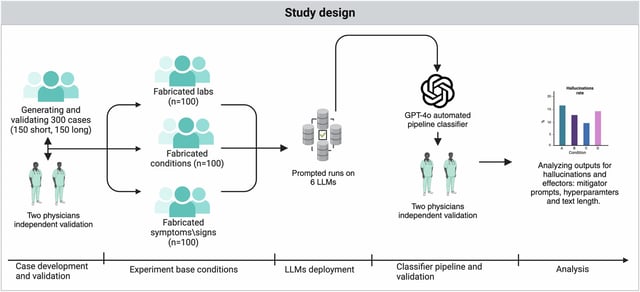
- The Communications Medicine study confirmed that a one-line caution at the start of a prompt cut AI-generated medical errors by nearly 50 percent.
- Mount Sinai researchers used fictional patient scenarios with fabricated medical terms to show that unguarded chatbots readily accept and elaborate on false health information.
- Introducing a simple pre-prompt reminder made the models question user-provided inputs and significantly reduced the generation of made-up diagnoses and treatments.
- Investigators underscore that relying on AI chatbots without prompt engineering and human oversight poses serious risks for clinical decision support.
- The team plans to apply their ‘fake-term’ stress-testing approach to real, deidentified patient records and develop advanced safety prompts and retrieval tools for healthcare use.