


Overview
- GDPval tests 1,320 realistic, file-based assignments across 44 occupations in nine top GDP industries using tasks authored by professionals averaging 14 years of experience.
- Blind human graders evaluated outputs from multiple models and human experts, with an AI autograder released as an experimental research tool to supplement—not replace—human scoring.
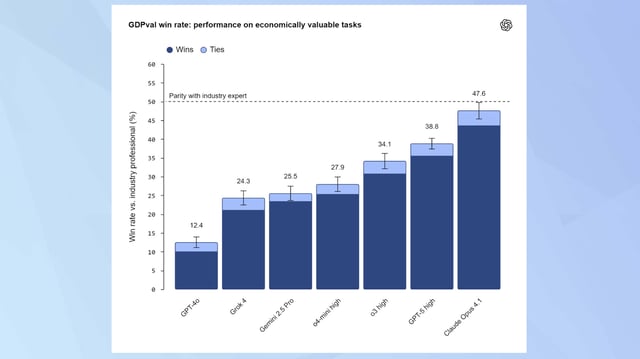
- TechCrunch reports GPT-5-high matched or beat experts 40.6% of the time and Claude Opus 4.1 49%, with OpenAI noting Claude’s edge in aesthetics and GPT-5’s strength in accuracy.
- OpenAI says models completed tasks roughly 100× faster and 100× cheaper than experts, a figure limited to inference time and billing that excludes oversight, iteration, and integration costs.
- Performance has advanced sharply since GPT-4o, and OpenAI plans to release subsets of GDPval tasks and expand the benchmark to interactive and context-rich workflows while cautioning against reading the results as evidence of imminent broad job replacement.