
Overview
- MIT researchers at the Improbable AI Lab have improved AI safety using a new machine learning approach for red-teaming.
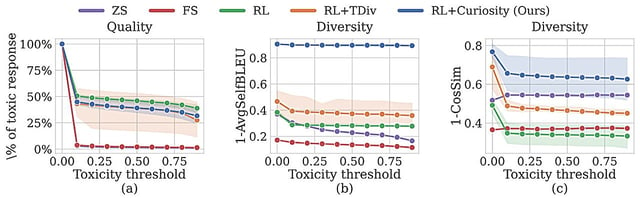
- The new method outperforms traditional human-led red-teaming by generating a broader range of prompts that trigger toxic responses from AI.
- This technique, based on curiosity-driven exploration, encourages the generation of novel prompts, enhancing the effectiveness of safety tests.
- The enhanced method can also detect toxic responses in chatbots previously deemed safe by human experts.
- The research aims to make AI model verification faster and more scalable as AI becomes more integrated into daily life.