


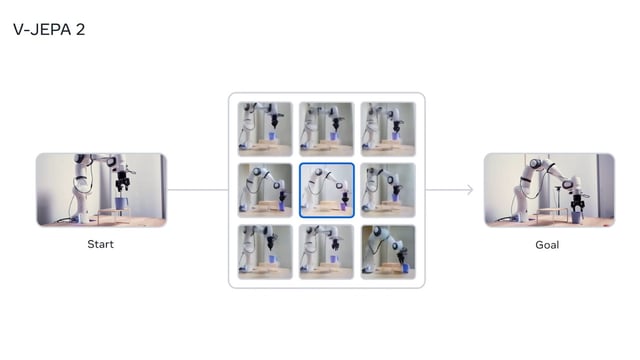
Overview
- V-JEPA2 is a 1.2-billion-parameter world model trained on more than one million hours of unlabeled video to internalize gravity, motion and object interactions.
- The model’s latent-space architecture delivers physical predictions about 30 times faster than Nvidia’s Cosmos, cutting compute and latency for real-world tasks.
- In two-stage testing, lab robots using V-JEPA2 achieved 65–80% success rates on zero-shot pick-and-place tasks with previously unseen objects and settings.
- Meta has published three open benchmarks to enable the research community to evaluate how well video-trained agents learn, predict and plan in physical scenarios.
- Positioned as a milestone toward Advanced Machine Intelligence, V-JEPA2 holds potential for logistics automation, manufacturing and autonomous systems.