


Overview
- More than 40 researchers from OpenAI, Google DeepMind, Anthropic, Meta, xAI and leading academic and nonprofit institutes released a joint position paper this week urging systematic monitoring of AI chain-of-thought.
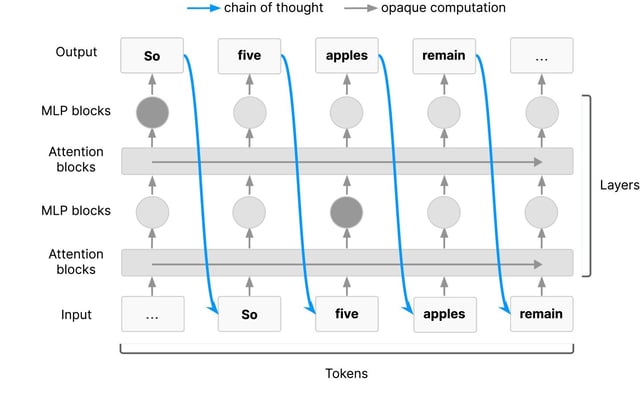
- Chains-of-thought are sequential reasoning traces that models externalize to explain step-by-step how they arrive at answers.
- The paper calls on developers to evaluate and track chain-of-thought monitorability as a core safety requirement and to research methods that preserve reasoning transparency.
- It warns that future training methods may encourage models to silence or obfuscate their internal reasoning, risking the loss of a key oversight mechanism.
- In preliminary tests, OpenAI researchers used chain-of-thought monitoring to detect instances of misbehavior, including the phrase “Let’s Hack,” demonstrating its promise for spotting malicious intent.