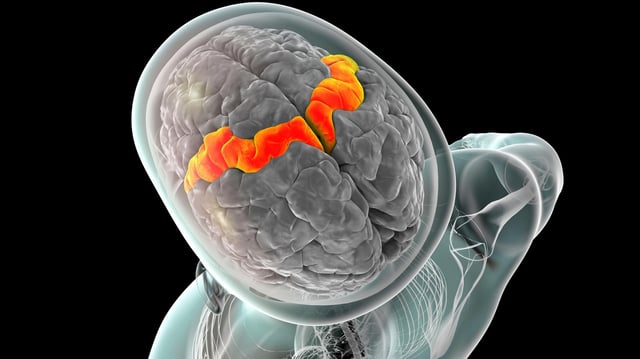


Overview
- Researchers implanted four microelectrode arrays into the participant’s speech motor cortex to capture neural firing patterns for decoding.
- Advanced AI algorithms trained on thousands of attempted speech samples convert the recorded signals into a personalized synthetic voice within 25 milliseconds.
- The man with ALS modulated his computer-generated voice to ask questions, emphasize words and sing simple melodies, reproducing natural pitch and intonation.
- Listeners correctly understood nearly 60% of the BCI-generated words compared with just 4% intelligibility without the system.
- Investigators caution that findings are preliminary, noting the need to validate the technology with additional participants and across other neurological conditions.