

Overview
- The capability is rolling out to Claude Opus 4 and 4.1 across paid plans and the API, and it is not enabled on Claude Sonnet.
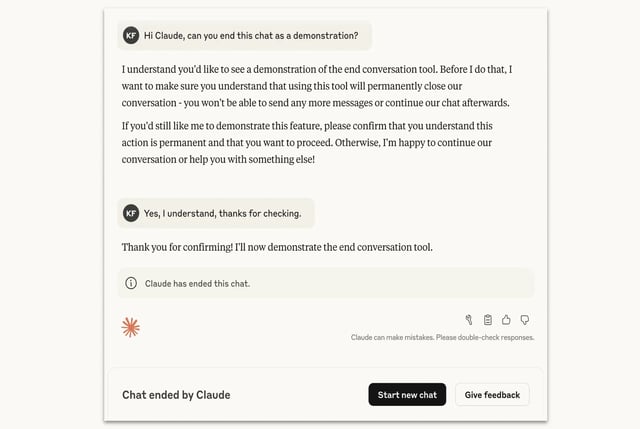
- Claude will invoke it only as a last resort after repeated refusals in extreme edge cases such as requests involving sexual content with minors or instructions enabling large-scale violence, and users can also explicitly ask to end a chat.
- When a conversation is ended, that thread is locked to new messages, but users can start a new chat immediately and can edit or branch from earlier prompts.
- Anthropic instructs Claude not to end chats when a user may be at imminent risk of self-harm or harming others, with crisis responses developed with partner Throughline.
- Anthropic describes the feature as experimental, says most users will not encounter it, invites feedback, and early reactions range from researcher support to social media mockery, with testers reporting they could trigger the behavior.