

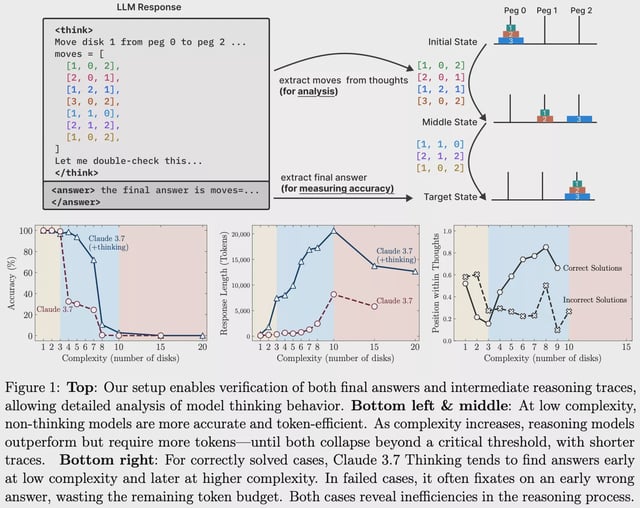
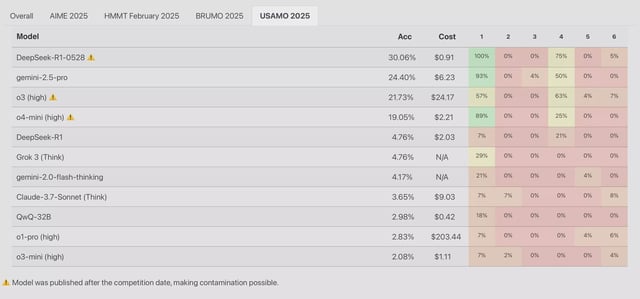
Overview
- Apple researchers found that leading AI models reliably solved Tower of Hanoi puzzles with three disks but error rates soared as disk counts increased, with models misstating rules and contradicting earlier steps.
- Additional tests on block-stacking and river-crossing puzzles showed a complete accuracy collapse beyond basic configurations, highlighting a broader failure in simulated reasoning under higher complexity.
- Observers including Gary Marcus argue these results demonstrate that LLMs rely on pattern matching rather than consistent logical processes, casting doubt on their suitability for advancing toward AGI.
- A rebuttal by Alex Lawsen counters that the observed shortcomings may stem from the design of evaluation frameworks rather than inherent flaws in the AI models’ reasoning abilities.
- Researchers and industry voices advocate hybrid approaches—integrating symbolic logic, formal verifiers or task-specific constraints—to address both real reasoning gaps and limitations of current testing methods.