

Overview
- An arXiv preprint details an Adversarial Instructional Prompt attack that manipulates instructional prompts to covertly alter retrieval behavior in RAG, reporting attack success rates up to 95.23% while preserving normal utility.
- New practitioner guidance stresses systematic validation of RAG outputs with faithfulness, relevance, and toxicity metrics, plus human escalation for low‑confidence or high‑risk responses.
- Recommended tooling spans RAGAS, LangChain evaluators, LlamaIndex, PerspectiveAPI, and Label Studio, with source linking and continuous monitoring highlighted for auditability.
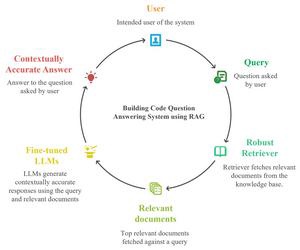
- A University of Alberta study on building‑code QA found Elasticsearch the most effective retriever, top‑3 to top‑5 documents sufficient for context, and Llama‑3.1‑8B fine‑tuning delivering a ~6.83% relative BERT F1 gain.
- A fresh architecture playbook outlines trade‑offs across centralized vs distributed retrieval, hybrid dense‑sparse search, offline vs online embeddings, and reliability measures such as fallbacks and observability.