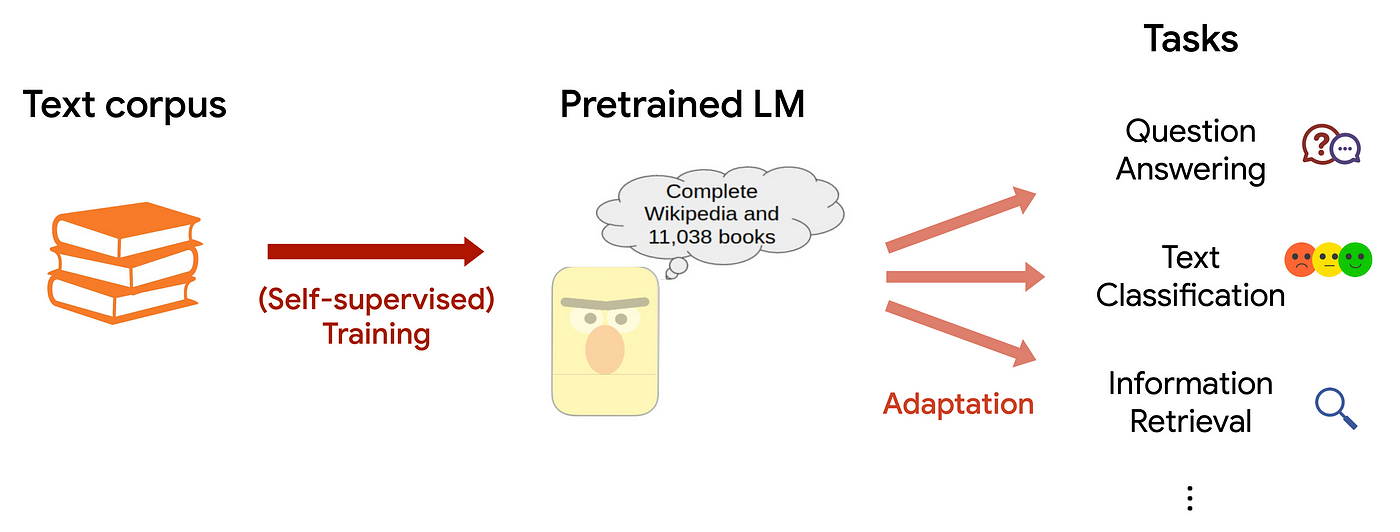
In linguistics and natural language processing, a corpus or text corpus is a dataset, consisting of natively digital and older, digitalized, language resources, either annotated or unannotated. From Wikipedia
Corpus analysis determined which viral slang, practical terms or cultural coinages were sufficiently enduring for inclusion.